

学生科研|pg麻将胡了试玩 2024年大学生创新创业训练计划结题优秀项目展示(二)
大创项目结题答辩会议
pg麻将胡了试玩 始终坚持以学生成长为中心,深度融合本科生导师制与学生大创项目,全方位助力学生科研创新能力培养。现对2024年大学生创新创业训练计划中12个结题优秀的项目进行展示,这些项目成果不仅彰显了信管学子的创新思维与实践能力,同时将为下一年度的大创项目申报提供灵感源泉与行动标杆,激励更多学子开启更为多元、更深层次的创新创业探索之旅。
项目一:基于大语言模型的政策文件分析系统搭建
团队成员:张可欣、陈俊兰、张语轩、冯杨阳
指导老师:李岱峰
一、项目简介
在人工智能与大数据快速发展背景下,本项目构建了一体化大语言模型开发应用平台,旨在解决数据分散、训练成本高、领域化难和应用门槛高等痛点。通过数据集管理、提示词优化、模型训练与微调等模块,一站式支持从数据获取、分析到定制化模型应用。创新点包括整合多元数据源、自动化模型评优机制与领域定制化方案,能有效满足政府采购等特定行业需求,提升产业应用效率与智能化水平,为企业降本增效并加速数字化转型进程。
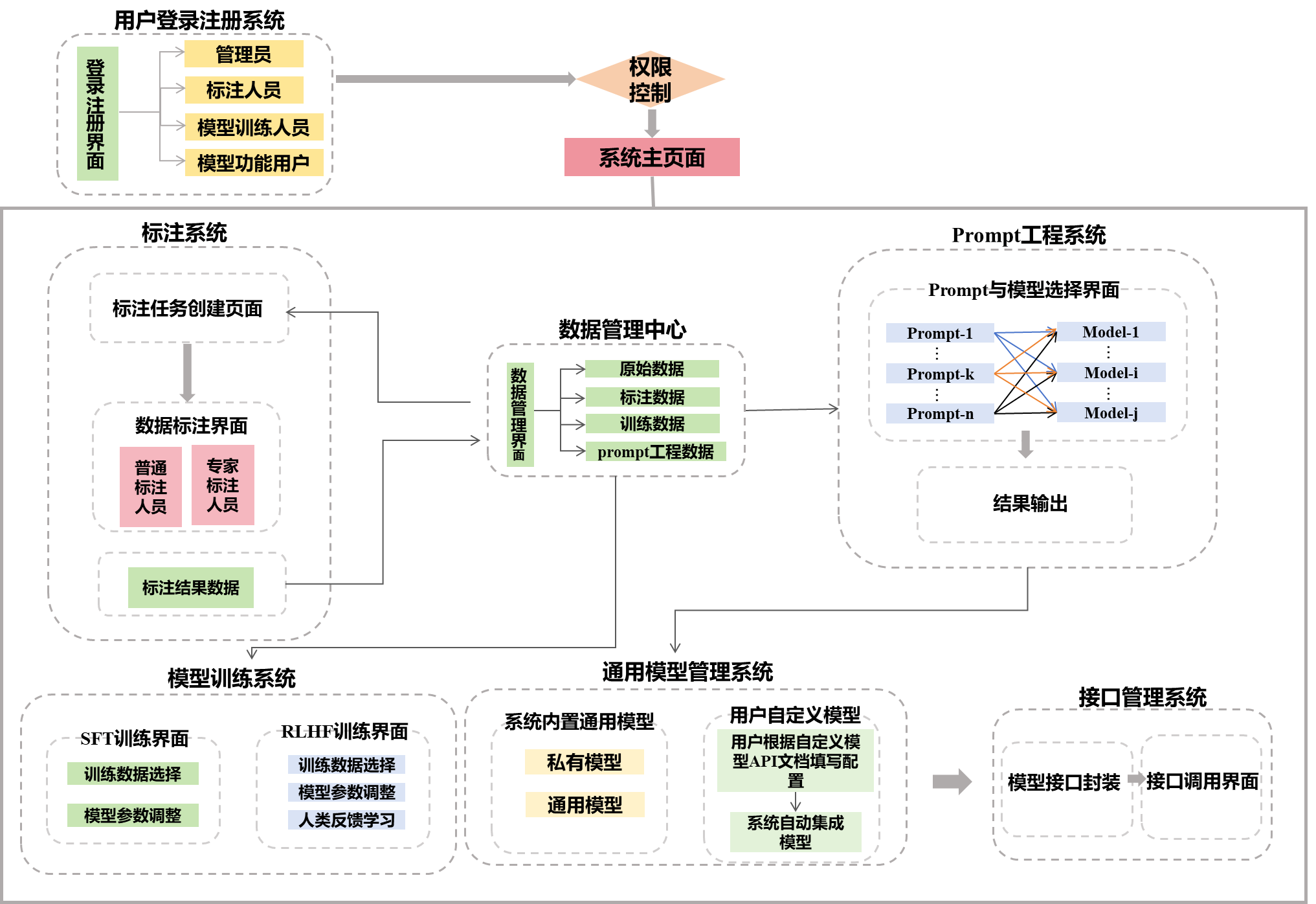
图1 系统架构
二、成果简述
本项目成功构建了一体化大语言模型开发应用平台,获得2024年(第十九届)海峡两岸暨港澳地区大学生计算机创新作品赛广东省赛三等奖,并已落地于学院校企合作“政府采购融合知识图谱的大语言模型关键技术研究”项目。在成果方面,平台实现了从数据采集、清洗、情报分析、模型优化到应用调用的全流程集成,大幅降低行业应用门槛。在实践中,本项目提出细化的数据集管理、自动化评优机制及领域化场景定制策略,为政府采购文件处理等复杂场景提供一站式智能解决方案。同时项目成果已初步在学术方向进行拓展,正在筹备论文发表与技术推广,加速技术成果转化与应用。

图2 合作基地
三、收获与体会
通过项目实施,团队在大数据传输、架构设计和协作能力上取得显著提升,积累了应对复杂问题的实战经验。然而,初期架构设计耗时、技术预研效率不足等问题仍待改进。对多端部署、高并发负载均衡、知识图谱领域适配性等关键技术还需深入研究。开发中曾遇到Flume自定义处理、动态路由配置、相似度计算优化等困难,团队借助多线程、协处理器和缓存策略逐步解决。建议后续加强资源分配与预研规划,为后期应对更复杂业务与技术挑战打下基础。
项目二:社交媒体虚假健康信息风险评估文化
团队成员:杜昊阳(负责人)、王健凯
指导老师:陈明红
一、项目简介
近年来,随着社交媒体的迅速普及和公众健康意识的逐步提高,越来越多的健康信息开始通过社交媒体传播,为公众获取健康信息提供了极大便利的同时,也促进了虚假健康信息的传播,对公众健康造成潜在风险。
本项目旨在综合采用文献调研、模型构建、机器学习与回归分析研究社交媒体虚假健康信息风险评估及影响因素,为评估社交媒体虚假健康信息风险提供指导与建议,减少社交媒体虚假健康信息对人们的负面影响。
二、成果简述
(1)采用机器学习模型评估社交媒体虚假健康信息风险,将社交媒体虚假健康信息风险分为低风险、中风险和高风险。
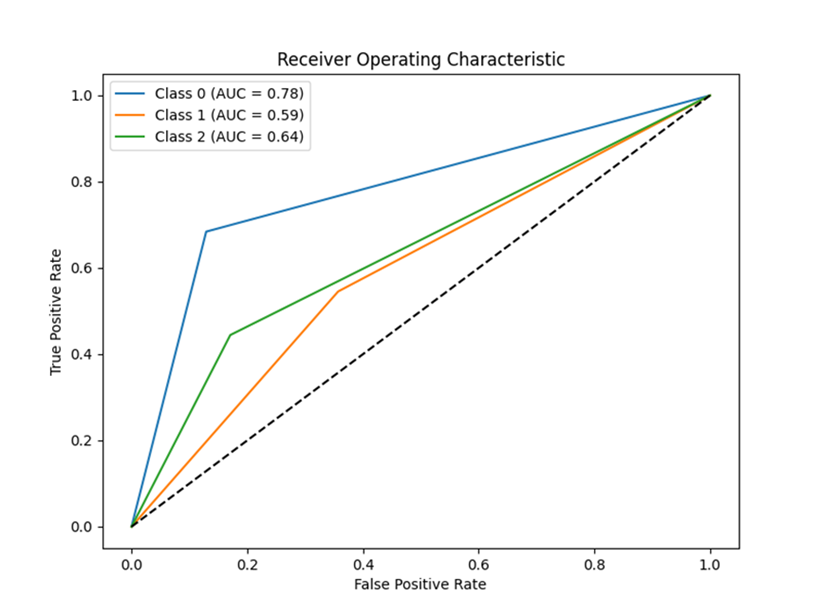
图1 ROC曲线
(2)运用回归分析验证与探究风险影响因素。
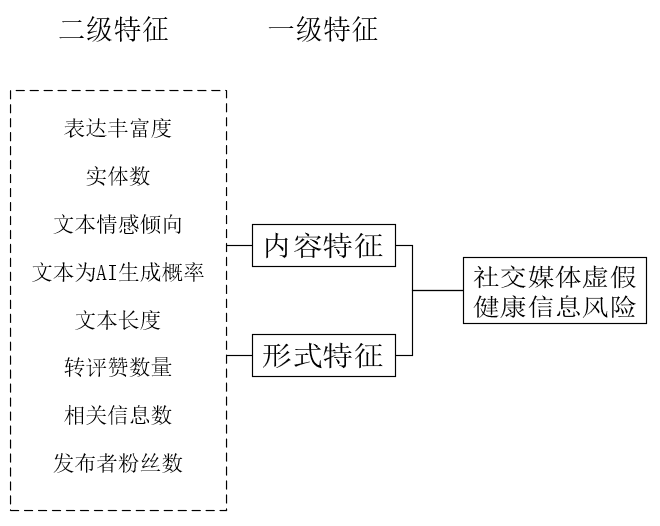
图2 社交媒体虚假健康信息风险影响因素示意图
三、收获与体会
在本次项目中,我们明白了如何从理论到实践,获得了编程与数据分析等实践技能的提升,同时对跨学科知识融合有了更深的体会,并收获了许多项目管理经验。
项目仍存在以下不足之处,未来可以在解决以上不足之处的基础上,进一步展开研究。
(1)数据集大小和多样性有限,可能影响了模型训练和拟合的效果。
(2)特征选择的深度与广度有待提升,仍有一些风险影响因素有待挖掘。
(3)数据标注具有主观性,可能导致风险等级评定不够精确。
项目遇到的挑战以及建议,主要有以下两点:研究的初步设想与实际的研究情况可能会有出入,要根据项目实际情况调整具体研究方法,转变思路也许会获得新的灵感;当遇到难以解决的问题时,要及时且主动地与导师沟通,导师往往会给予非常关键的建议。
项目三:生成式人工智能在知识组织中的应用研究与实践
团队成员:潘昊翔(负责人)、黎珮仪、赵荣彬、苏隽
指导老师:余维杰
一、项目简介
随着生成式人工智能(Generative AI)的迅速发展为知识组织工作带来了变革契机。传统的知识组织方式通常耗时费力且难以处理大规模的多源数据,因此研究生成式AI在知识组织中的应用实践,对于未来的知识组织工作具有重要的理论价值与实践意义。
本研究的目的在于对比研究国内外生成式AI完成知识组织任务情况,并且探索生成式AI的交互流程框架以使生成式AI完成知识组织任务时达到最佳效果。本项目的特色在于对生成式AI在知识组织中的应用进行实证研究,而创新之处在于对国内生成式AI的知识组织效果进行探究,以及对生成式AI 完成多模态知识组织任务的效果的探究。
二、成果简述
我们对知识组织任务划分多个情景,包括文献著录、分类标引、主题标引、本体构建、知识抽取与知识图谱构建,通过提问并收集其回答,对比了文心一言4.0、Chatgpt4o、kimi、智谱清言GLM 4 plus在知识组织任务中的表现。
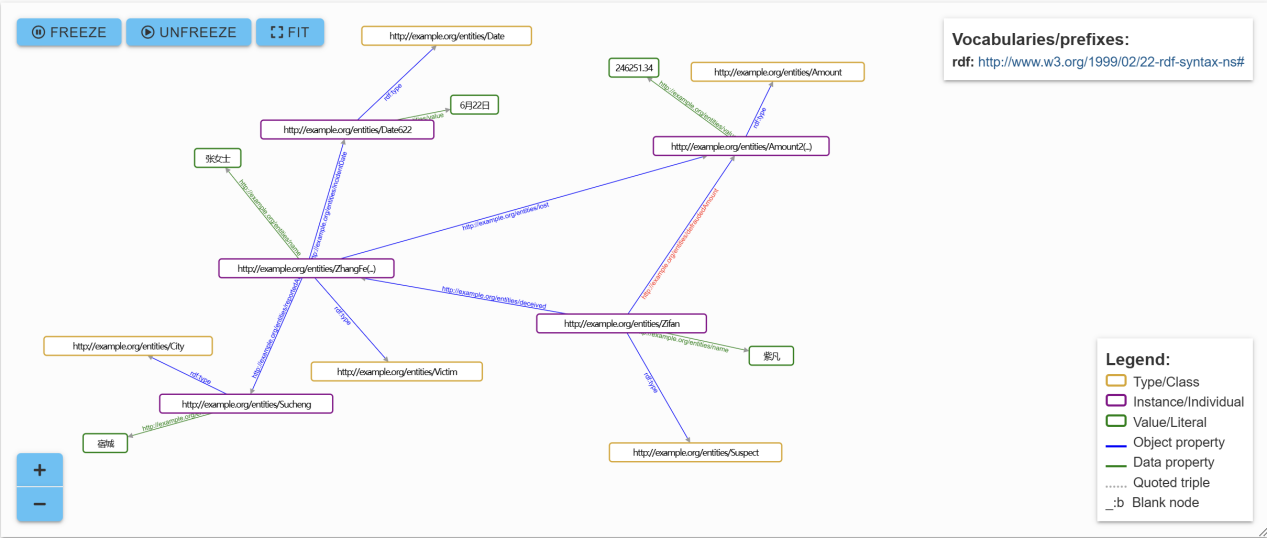
图 智谱清言完成文本知识图谱构建效果示例
通过实验,我们认为生成式AI能完成简单的知识组织任务与简单的本体构建,但是对于独立完成复杂知识组织任务能力有限,需要人工辅助保证完成效果。此外,我们提出了依次按照分解复杂任务、划分明确任务类型、逐步提示优化效果、不断追问和修正、最后检查是否符合预期的交互框架。
对于上述成果,我们提出了生成式AI需要增加跨学科研究、研究人员需要深化专业知识的建议,并形成了一篇研究报告。
三、收获与体会
在项目实施中,对于生成式AI的能力有了更深刻的体会。生成式AI在借助语料库甚至于联网检索的情况下能够完成简单的知识组织任务,也能够在使用者的引导下完成部分复杂知识组织任务,但目前还无法独立完成复杂的任务。这说明虽然生成式AI虽然有完成任务的能力,但并不代表使用者只需要生成式AI而不需要专业能力,相反使用者需要更高的专业素养去引导生成式AI更好完成任务。
项目四:本科生考试档案整理规范编制研究——以中山大学为例
团队成员:杭飞宇(负责人)、刘苏玛、胡兴旺、谷苡萌
指导老师:杨利军
一、项目简介
中山大学档案馆在考试文件归档工作中面临着缺少规范管理文件的问题,需要制定详尽且有约束力的方案来指导考试文件的归档工作。
项目在理论层面能丰富高校档案管理理论;在实践层面,项目成果能直接“落地”指导中山大学考试档案的管理工作。
项目研究内容既符合学生团队的专业背景,也确保了项目的可行性和实施难度的适中,对学生的成长和创新能力培养起到积极作用。
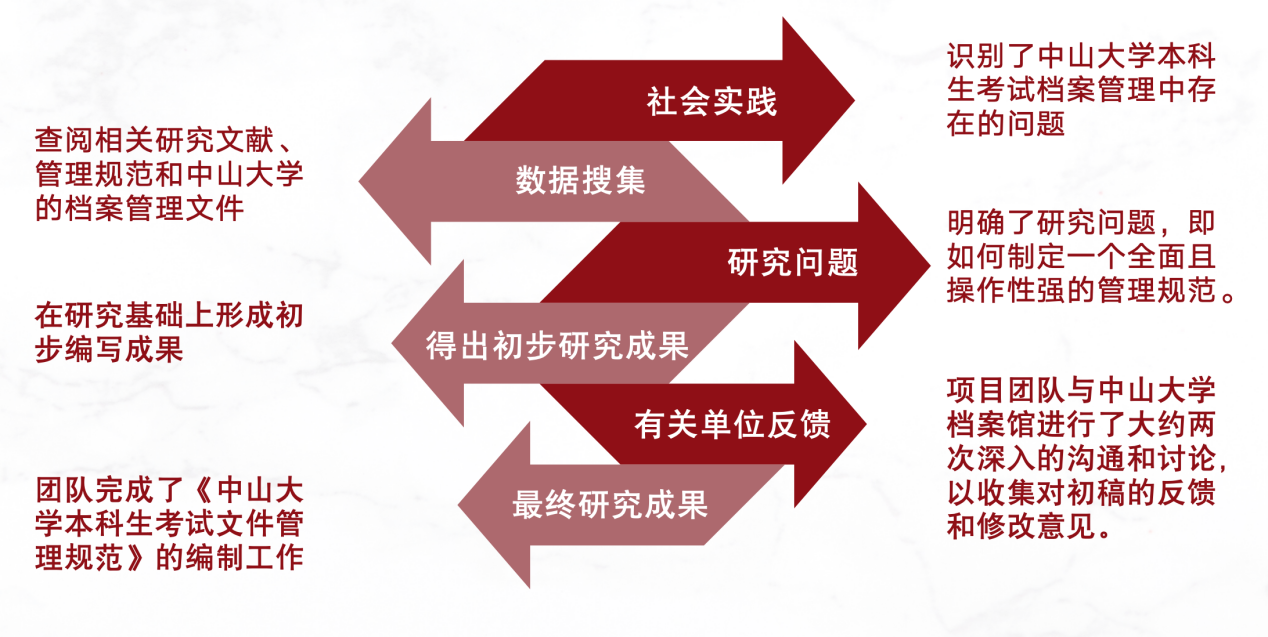
图1 调研过程
二、成果简述
项目最终成果为《中山大学本科生考试档案管理规范》。在该“规范”中,(1)明确了考试档案的收集对象和范围,确保档案收集的全面性和系统性;(2)项目提出了详细的档案整理流程,包括分类、编目、排列、装订等内容,以提高档案的系统和可检索性,确保档案信息的准确和有序;(3)项目同时对考试档案的移交及保管年限做出了明确规定,增强了档案管理的可操作性和实用性。
三、收获与体会
通过项目的推进,项目团队成员的专业能力得到提升;通过深入接触档案管理实际流程,将课程理论知识融入实践,熟练掌握了多种研究方法,学会挖掘关键信息,精准分析问题。同时,通过项目的分工与协作,团队成员认识到团队合作重要的重要性。最后,团队成员切身体会到“理论来源于实践又反过来指导实践”的道理,进一步提升了社会责任感,深刻认识到学以致用、服务社会的重要性。
项目对考试类型多样性估计不足,像体育等具有特殊考试文件的考试,未进行全面调查。后续尚需围绕特殊之处,制定有针对性的管理规定。

